xG nelle Scommesse sul Calcio: Come Usare i Gol Attesi per Trovare Quote Sottovalutate

I gol attesi misurano la qualità dei tiri, non il caso. E il gap tra l’xG di una squadra e i risultati effettivi in un dato periodo è quasi sempre materia prima per trovare quote sottovalutate — a condizione di saperlo leggere. Ho capito questo abbastanza tardi nella mia carriera di analista: per anni guardavo la classifica finale e il numero di gol come indicatori principali. Quando ho iniziato a lavorare con i dati xG, la prospettiva è cambiata completamente.
L’expected goals, o xG, è una metrica statistica che quantifica la probabilità che un tiro si trasformi in gol, basandosi su una serie di variabili osservabili al momento del tiro: distanza dalla porta, angolo, tipo di tiro, situazione di gioco, pressione difensiva, se è un colpo di testa o un tiro col piede. Un tiro da 5 metri al centro della porta senza difensori ha un xG vicino a 1. Un tiro da 30 metri sul lato ha un xG di 0.02-0.03. Sommando tutti i tiri di una squadra in una partita si ottiene l’xG totale: indica quanti gol quella squadra “avrebbe dovuto” segnare in base alla qualità delle occasioni create.
Il modello xG Bayesiano sviluppato dalla Deakin University e validato su PMC/NIH nel 2024 raggiunge un’Area Under Curve di 0.781 con sole 7 variabili, sostanzialmente comparabile al modello StatsBomb con AUC 0.801 che ne usa molte di più. Questo è il punto centrale: non serve un sistema complicatissimo per costruire una stima utile. Serve usare xG in modo sistematico e disciplinato.
Questa guida spiega cos’è l’xG in dettaglio tecnico, come convertire i dati xG in probabilità di partita e poi in stima di edge, perché la Serie A presenta specifiche caratteristiche di liquidità e come leggere il mercato prima che si muova attraverso l’allibramento delle quote.
Indice dei contenuti
- Cos’è l’xG e Perche’ il Risultato Non Racconta Tutta la Storia
- Dal Dato xG alla Quota: Come Costruire la Propria Stima di Probabilita’
- Serie A e xG: I Mercati con Maggiore Liquidita’ e i Limiti delle Statistiche nelle Serie Minori
- Allibramento e Quote Virgine: Come Leggere il Mercato Prima che Si Muova
- Oltre l’xG: Transformer, Modelli Bayesiani e Machine Learning nelle Previsioni Calcio
- Dove Trovare Dati xG Affidabili per il Calcio Italiano: Fonti Gratuite e Premium
- Domande sull’xG nelle Scommesse sul Calcio
- xG non è una Formula Magica, ma è il Miglior Punto di Partenza
Cos’è l’xG e Perche’ il Risultato Non Racconta Tutta la Storia
Lazio-Juventus 2-0 il martedì sera. La Juventus ha perso, la quota era 2.20 sulla vittoria bianconera. Sbagliato puntarci? Forse no. Se la Juventus aveva xG 2.4 e la Lazio xG 0.9, il risultato è stato influenzato dalla fortuna del momento. Sul lungo periodo, squadre che producono xG superiori al risultato effettivo tendono a “recuperare” nelle partite successive — e questa regressione verso la media è esattamente il tipo di inefficienza che il mercato spesso non prezza correttamente nella quota della partita successiva.
Le 7 variabili del modello Deakin University sono quelle che spiegano meglio la probabilità di gol su ogni singolo tiro: distanza dal portiere, angolo rispetto alla porta, se si tratta di un tiro di testa o col piede, se l’assist è stato un cross o un passaggio filtrante, se il tiratore era sotto pressione difensiva immediata, se il tiro è stato un tap-in da azione di rimbalzo, e la situazione di gioco (azione manovrata, calcio piazzato, contropiede). Queste variabili spiegano la maggior parte della varianza tra tiro e gol nella Serie A e nelle principali leghe europee.
La differenza tra xG “for” e xG “against” è il dato che uso di più nell’analisi pre-partita. Una squadra con xG for medio di 1.8 e xG against di 0.9 per partita è strutturalmente molto più forte di una che ha gli stessi risultati in classifica ma con xG 1.1 for e 1.3 against — la seconda potrebbe avere un portiere straordinario che regge risultati non sostenibili nel medio periodo. L’analisi xG for/against su finestra rolling di 6-8 partite è la base del mio processo di analisi pre-match sulla Serie A.
Una precisazione importante: l’xG non spiega tutto. Non cattura la qualità del portiere (un portiere eccellente riduce la conversione reale rispetto all’xG against), non cattura eventi rari come le reti di testa su angolo diretto, e non spiega la performance individuale dei singoli giocatori nel convertire occasioni difficili. Per questi motivi i modelli avanzati — come il post-shot xG, che calcola l’xG basandosi su dove effettivamente ha colpito il tiratore invece che sulla posizione del tiro — offrono una stima ancora più precisa, ma richiedono dati Opta o StatsBomb non sempre disponibili gratuitamente.
Dal Dato xG alla Quota: Come Costruire la Propria Stima di Probabilita’
Avere i dati xG è solo il primo passo. Il secondo — quello che molti non fanno mai — è convertirli in probabilità di partita utilizzabili per calcolare l’edge rispetto alle quote del bookmaker. Il processo non è immediato, ma è riproducibile e migliorabile con la pratica.
Passo 1: calcola l’xG medio per partita di ciascuna squadra sulle ultime 6-8 partite, separando le partite in casa da quelle in trasferta. Il contesto casa/trasferta ha un impatto significativo — nella Serie A, che attrae il massimo volume di scommesse in Italia tra tutti i campionati, il vantaggio del fattore campo è ben documentato e deve essere incorporato nella stima.
Passo 2: applica un peso maggiore alle partite recenti. Una partita di 8 settimane fa vale meno di una di 2 settimane fa per catturare la forma attuale della squadra. Un sistema semplice: peso 1 per le partite 1-2 settimane fa, 0.8 per le partite 3-4 settimane fa, 0.6 per le partite 5-8 settimane fa.
Passo 3: usa il modello di Poisson per convertire i lambda (xG medi attesi per ciascuna squadra nella partita specifica) in probabilità di risultato. La distribuzione di Poisson descrive il numero di eventi in un intervallo di tempo dato un tasso medio di occorrenza — ed è la stima più usata nei modelli calcistici per il numero di gol. Con lambda_casa = 1.5 e lambda_trasferta = 0.9, la distribuzione di Poisson genera probabilità per ogni possibile risultato esatto (0-0, 1-0, 0-1, 1-1, ecc.) che si sommano a 1. Aggregando i risultati si ottengono le probabilità di vittoria casa, pareggio e vittoria ospite.
Passo 4: rimuovi l’aggio dalle quote del bookmaker (vedi la sezione sulla quota reale nel contesto della guida al value bet nel calcio) e confronta le probabilità fair del bookmaker con le tue. Se la tua stima di vittoria casa è 52% e la probabilità fair del bookmaker è 47%, hai un edge del 5% — potenzialmente una value bet.
Passo 5: verifica la coerenza del segnale con altre fonti. Le Dropping Odds (quote in calo su più bookmaker) su quella stessa partita nella direzione della tua previsione sono un segnale di conferma: il mercato sharp sta prezzando la stessa informazione che hai identificato tu. Le Dropping Odds nella direzione opposta dovrebbero far riconsiderare la tua stima.
Un esempio pratico sulla Serie A: Milan vs Fiorentina, stagione 2025-26. Il Milan ha xG for media delle ultime 6 partite di 1.8 in casa, la Fiorentina ha xG against media di 1.4. Il modello Poisson con lambda_Milan = 1.65, lambda_Fiorentina = 0.95 genera: vittoria Milan 54%, pareggio 24%, vittoria Fiorentina 22%. La quota bookmaker sull’1 è 2.00, che dopo rimozione aggio corrisponde a una probabilità fair del 48%. La differenza di 6 punti percentuali rappresenta un edge del 6% — zona d’oro.

Serie A e xG: I Mercati con Maggiore Liquidita’ e i Limiti delle Statistiche nelle Serie Minori
La Serie A è il campionato con il massimo volume di scommesse in Italia — ed è anche il più difficile su cui trovare edge con un modello xG semplice. Non è contraddittorio: è la diretta conseguenza dell’efficienza del mercato. Piu’ capitali si muovono su una partita, più il bookmaker ha incentivi a calibrare le quote in modo preciso, e più diventa difficile trovare discrepanze significative tra la stima del mercato e la realtà.
Il volume di scommesse sulla Serie A a livello globale è stimato intorno ai 34 miliardi di euro annui — un dato che posiziona il campionato italiano come uno dei mercati più liquidi al mondo dopo la Premier League. In un mercato così liquido, gli edge dell’1-3% sono rari e richiedono modelli molto più sofisticati del semplice Poisson con xG aggregato. I mercati della Serie A dove si trovano ancora edge con modelli relativamente semplici sono quelli secondari — under/over 2.5 gol nei mercati infrasettimanali, gol nel primo o secondo tempo, e in alcune circostanze il mercato degli angoli.
La Serie B è un livello di efficienza inferiore. I bookmaker aggiornano i modelli con meno frequenza sulle squadre di B, specialmente nelle prime 6-8 giornate di stagione quando i dati sono scarsi. Un analista che lavora con xG sulla Serie B con dati FBref — che copre il campionato italiano di B con buona qualità — ha un vantaggio informativo reale rispetto al mercato medio. Gli edge del 4-8% sono trovabili con più frequenza rispetto alla A.
La Serie C è un territorio diverso: i dati xG di qualità sono quasi inesistenti sulle fonti gratuite, le squadre hanno ampi movimenti di rosa tra stagioni che rendono il dato storico poco predittivo, e la liquidità dei mercati è spesso insufficiente per puntate di dimensione utile. Chi vuole operare sulla Serie C deve costruire il proprio dataset di dati di tiro da fonti come WhoScored o pagare per accesso a Opta, e deve accettare margini di incertezza molto più alti sulla qualità delle stime.
Il confronto più utile è questo: in Serie A si trovano meno edge ma su un mercato liquido e trasparente. In Serie B si trovano edge più frequentemente su un mercato meno efficiente. In Serie C/D l’edge potenziale è alto ma il rischio di stima è molto più elevato e i mercati hanno liquidità molto bassa. La strategia ottimale per un analista semi-professionale che usa l’xG è di concentrarsi sulla Serie A per i mercati secondari e sulla Serie B per i mercati principali — dove il livello di competenza richiesto è bilanciato con l’accessibilità dei dati.

Allibramento e Quote Virgine: Come Leggere il Mercato Prima che Si Muova
Questa distinzione tra mercati ad alta e bassa efficienza ha una conseguenza pratica immediata: il valore delle informazioni dipende dal momento in cui le ottieni. Sui mercati liquidi come la Serie A, la finestra di vantaggio si apre e si chiude molto rapidamente — e per coglierla serve capire come le quote si formano prima che il volume retail le “contamini”. Qui entra l’allibramento.
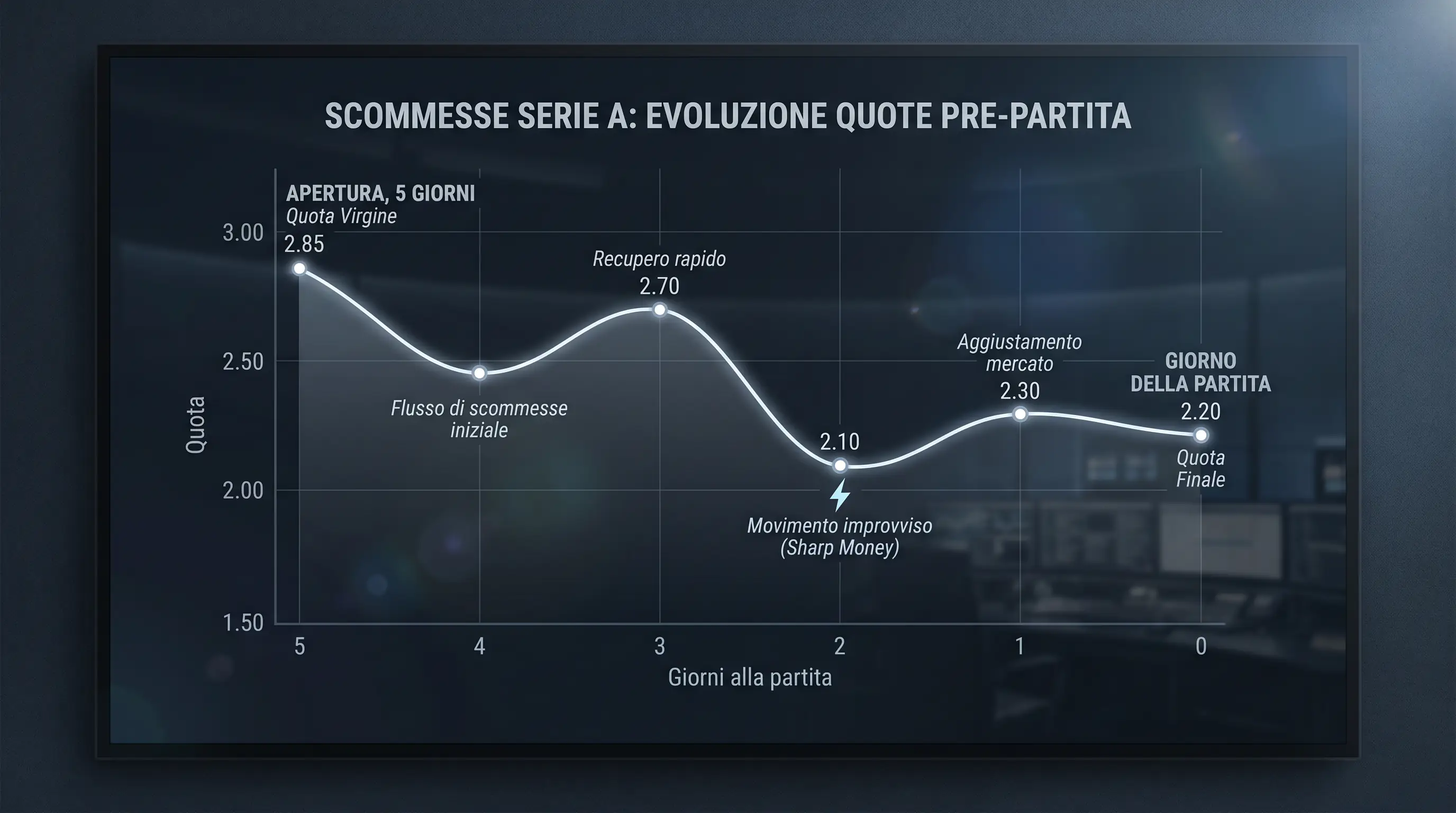
Quando apro le quote di una partita di Serie A il lunedì mattina e vedo la squadra di casa a 2.10, quello che sto vedendo non è necessariamente la stima di probabilità del bookmaker — è già la quota dopo ore o giorni di movimento di mercato. La quota virgine (opening line) era diversa. E la differenza tra dove la quota ha aperto e dove si trova ora è informazione.
L’allibramento è il processo con cui il bookmaker costruisce la prima quota prima che il mercato si apra al pubblico. In questa fase, i bookmaker sharp come Pinnacle e i grandi exchange come Betfair stabiliscono la linea iniziale basandosi esclusivamente sui propri modelli statistici — senza influenza del volume retail. Questa opening line è la stima di probabilità più “pura” disponibile: non contiene ancora il rumore delle scommesse dei giocatori comuni.
Quando la quota si muove dalla opening line alla current line, sta accadendo una delle cose seguenti. Primo: smart money (scommettitori professionali o sharp) hanno puntato in modo significativo su un lato, forzando il bookmaker ad aggiustare la quota per bilanciare il libro. Secondo: informazione privata si è diffusa nel mercato — un infortunio non comunicato ufficialmente, un problema tattico noto all’entourage — e qualcuno ha agito prima della notizia pubblica. Terzo: puro volume retail ha spostato la quota in modo non informativo.
Come distinguere i movimenti informativi da quelli di rumore? Il segnale più affidabile è la concordanza su più bookmaker e su più tipi di mercato. Se la quota scende solo su un bookmaker, potrebbe essere un aggiustamento di libro locale. Se scende su 4-5 bookmaker contemporaneamente senza news pubblica, sta succedendo qualcosa che il mercato sta prezzando prima del comunicato ufficiale. Se allo stesso tempo scende la quota “gol si” nella stessa partita, c’è probabilmente informazione su un cambio tattico.
Il modello operativo che uso: seguo le opening line di Pinnacle dal momento in cui aprono, tipicamente 4-6 giorni prima della partita. Confronto con il mio modello xG aggiornato. Se c’è discrepanza significativa (il mio modello dice 52% ma Pinnacle apre a 47%), ho una finestra di opportunità — o il mio modello ha trovato un’inefficienza, o il mio modello è sbagliato. La risposta arriva nei giorni successivi, quando il mercato aggrega ulteriore informazione. Se la quota di Pinnacle si muove verso la mia stima (da 47% implicito verso 50-52%), il segnale si rafforza. Se si muove nella direzione opposta, devo riconsiderare la mia analisi.
Le Quote Virgine non sono accessibili a tutti in tempo reale — richiedono monitoring attivo o strumenti specifici come OddsPortal con dati storici delle opening line, o l’accesso diretto alle piattaforme che aprono prima (Pinnacle, Bet365). Il vantaggio informativo dell’allibramento è massimo nelle 24-48 ore successive all’apertura, quando il mercato non ha ancora aggregato tutto il volume informativo disponibile.
Oltre l’xG: Transformer, Modelli Bayesiani e Machine Learning nelle Previsioni Calcio
Il modello Poisson con xG è un ottimo punto di partenza — ma il mercato professionale è andato molto oltre. Capire dove stanno i limiti del modello semplice e dove cominciano i modelli avanzati è utile per due motivi: per valutare cosa si sta usando e per capire contro chi si sta competendo quando si cerca edge nel mercato della Serie A.
Soccer Oracle è un caso concreto di cosa significa un modello Transformer applicato alle scommesse calcio. E’ un’architettura con 164.000 parametri addestrata sui dati della Serie A 2025-26 che raggiunge un hit rate del 71.1% su 187 segnali validati in 14 partite — e del 76.5% sui segnali generati a 15 minuti dall’inizio della partita, quando il contesto del primo quarto di gara è già incorporato nel modello. Rispetto a un modello Poisson standard, la differenza principale è che Soccer Oracle processa sequenze di dati (il flusso di eventi della partita) invece di una stima puntuale pre-match.
I modelli Bayesiani rappresentano un’evoluzione del Poisson che introduce prior informative — non si parte da zero su ogni squadra, si parte da una stima iniziale basata su dati storici e si aggiorna man mano che arriva nuova informazione. Il modello Deakin University con AUC 0.781 è un esempio di Bayesiano ben calibrato: la sua forza non è nella complessità architettonica ma nella scelta delle 7 variabili più predittive e nella metodologia di aggiornamento delle prior. Modelli simili, costruibili con Python e dati FBref, sono accessibili a chiunque abbia competenze statistiche di base.
Il Machine Learning per la gestione degli infortuni è un’area dove i club professionistici hanno dimostrato impatti misurabili: Liverpool e Manchester City hanno ridotto del 24% gli infortuni muscolari tra il 2018 e il 2021 usando modelli predittivi per gestire il carico di lavoro settimanale. Per lo scommettitore, l’implicazione pratica è diversa dalla prevenzione infortuni: le stesse fonti di dati di carico atletico usate dai club per gestire la rotazione possono essere integrate nei modelli predittivi per stimare quanto una squadra “fresca” perforerà rispetto a una con calendario fitto.
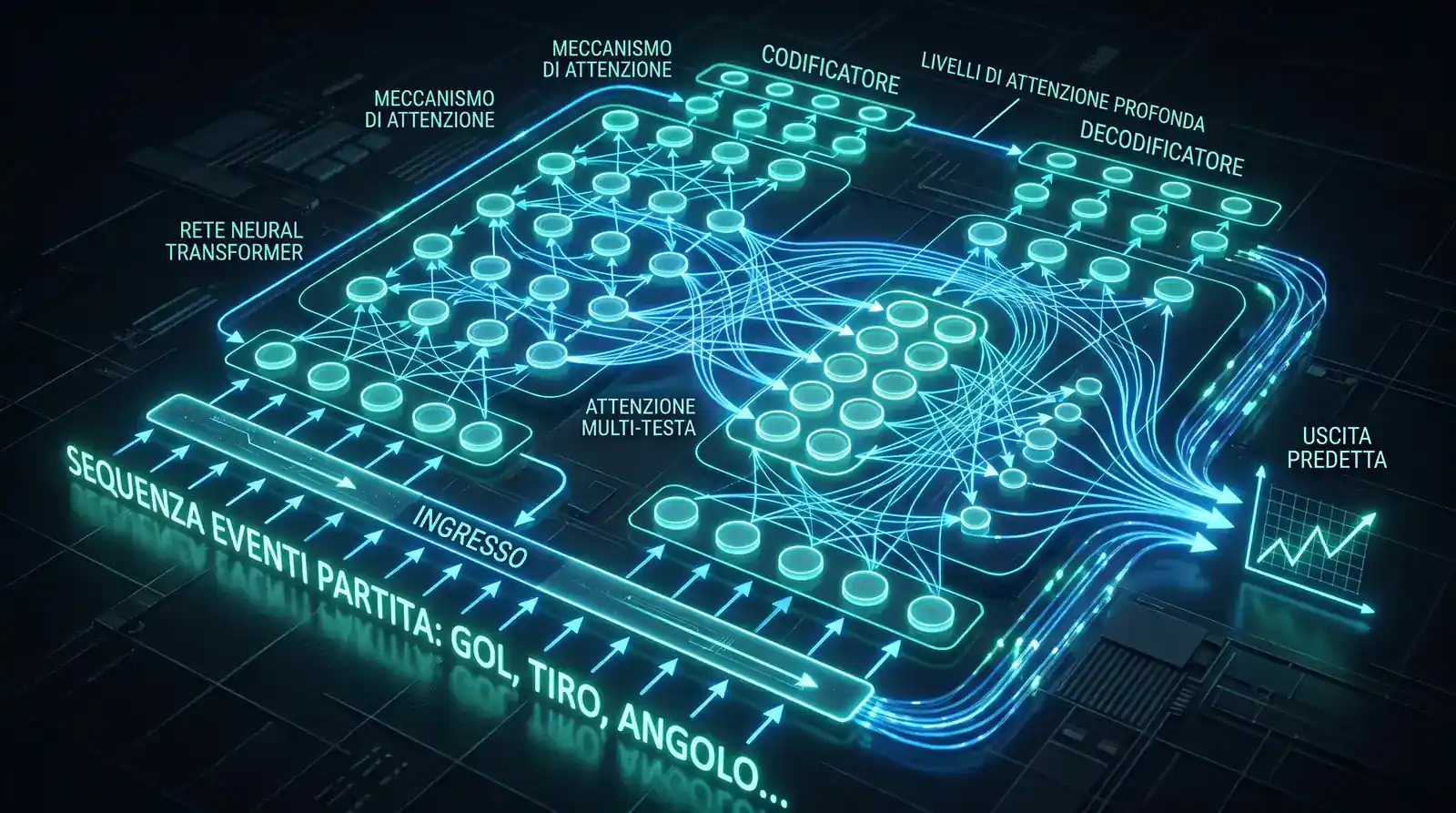
I limiti dei modelli avanzati sono reali. L’overfitting è il rischio principale: un modello addestrato su 3 stagioni di Serie A puo’ imparare pattern specifici di quelle stagioni che non si replicano nella successiva. La correlazione spuria — trovare relazioni statisticamente significative che non hanno senso causale — è più facile con più variabili e più dati. E il mercato stesso impara: se un’inefficienza viene sistematicamente sfruttata da abbastanza operatori, i bookmaker la correggono nella loro quotazione. Per approfondire gli strumenti IA disponibili con prestazioni verificate, la guida dedicata all’intelligenza artificiale nelle scommesse calcio tratta i casi Soccer Oracle e SuperFoglio con i dati prestazionali completi.
Dove Trovare Dati xG Affidabili per il Calcio Italiano: Fonti Gratuite e Premium
La qualità dei dati determina la qualità del modello. Una stima xG costruita su dati incompleti o con bias di raccolta è peggio di nessuna stima — ti dà falsa sicurezza su numeri sbagliati. Ecco le fonti che uso e come ne valuto i limiti.
Understat è la fonte gratuita più completa per le top 6 leghe europee, inclusa la Serie A. Copre dati xG per partita, per tiro, per giocatore. I modelli xG di Understat non sono stati pubblicati in peer review ma sono considerati affidabili dagli analisti della community. Il limite principale: nessuna copertura di Serie B o campionati minori italiani.
FBref (Football Reference) copre Serie A e Serie B con dati xG derivati dal modello StatsBomb. La qualità è alta, la copertura sulla Serie B è buona. FBref offre anche metriche avanzate come PPDA (Passes Allowed Per Defensive Action, un proxy dell’intensità difensiva) e pressione difensiva, utili per i modelli più sofisticati. Accesso gratuito con limitazioni sul numero di richieste API.
WhoScored offre dati su campionati non coperti da Understat e FBref, inclusa la Serie C in alcuni casi. La qualità dei dati xG è inferiore — usa un modello meno documentato — ma è spesso l’unica alternativa disponibile per le serie minori.
Opta (ora Stats Perform) è il provider premium di riferimento per i dati di tiro avanzati. Il post-shot xG — il dato più accurato disponibile — è esclusiva Opta. L’accesso richiede un abbonamento professionale che si giustifica solo se il volume delle puntate è abbastanza alto da amortizzare il costo. Per un operatore semi-professionale che punta 1.000-2.000 euro al mese, il costo Opta probabilmente non è giustificato.
StatsBomb offre accesso open-source per uso accademico e per alcuni dataset storici. Se stai costruendo un modello e vuoi usare dati ad alta qualità per la calibrazione iniziale, i dataset StatsBomb open-source sono un punto di partenza eccellente — ma la copertura temporale e geografica è limitata.

Domande sull’xG nelle Scommesse sul Calcio
Come si interpreta un valore xG nel contesto delle scommesse?
Un valore xG rappresenta la probabilità che un tiro si trasformi in gol basandosi sulle variabili al momento del tiro (distanza, angolo, tipo di tiro, ecc.). Nel contesto delle scommesse, il dato rilevante è la differenza tra xG totale e gol effettivi su una serie di partite: una squadra che segna meno dei suoi xG sta probabilmente attraversando una fase di sfortuna nel finalizzare, e il mercato potrebbe non averlo ancora incorporato nella quota. La media rolling su 6-8 partite è più utile del singolo dato di partita.
Qual è la differenza tra xG semplice e modello xG Bayesiano?
Il modello xG semplice calcola la probabilità di gol per ogni tiro basandosi su variabili osservabili e converte il totale in una stima di gol attesi per partita. Il modello xG Bayesiano aggiunge una prior informativa: parte da una stima iniziale basata su dati storici e aggiornamenti contestuali (stagione in corso, forma, fattore campo) e la affina progressivamente con nuovi dati. Il modello Bayesiano è più robusto per squadre con pochi dati disponibili (neopromosse, prime giornate di stagione) e riduce l’overfitting su campioni piccoli.
Dove si trovano i dati xG gratuiti per il calcio italiano?
Le principali fonti gratuite per l’Italia sono Understat (Serie A con copertura completa, no Serie B), FBref (Serie A e Serie B con modello StatsBomb, dati avanzati inclusi) e WhoScored (copertura più ampia di campionati minori con qualità dei dati inferiore). Per dati di qualità premium come il post-shot xG la fonte principale è Opta, con accesso a pagamento. Per uso accademico o costruzione di modelli di calibrazione, StatsBomb open-source offre dataset storici di alta qualità.
xG non è una Formula Magica, ma è il Miglior Punto di Partenza
Dopo anni a lavorare con i dati xG sulla Serie A, la conclusione più onesta che posso offrire è questa: l’xG non elimina l’incertezza del calcio, ma la struttura. Ti permette di distinguere la varianza normale — una serie di risultati sfortunati per una squadra che produce occasioni di qualità — dall’effettiva debolezza strutturale di una squadra che non crea niente. Questa distinzione, applicata sistematicamente con un modello calibrato, genera edge reali nel mercato delle quote.
Come sintetizzava Alessandro Trabassi di Stats4Bets: in un mondo in cui le scommesse sono troppo spesso guidate dalle sensazioni, l’analisi statistica è l’alternativa concreta. L’xG è lo strumento che rende operativo questo principio — non perché sia infallibile, ma perché è verificabile, riproducibile e migliorabile. Ogni modello che costruisci sulla base dell’xG puoi testarlo su dati storici, misurarne la calibrazione, aggiornarlo con nuove variabili.
Il passo successivo nella catena analitica è capire come i sistemi di intelligenza artificiale moderni — dalla Soccer Oracle ai modelli Transformer — integrano l’xG con variabili aggiuntive per arrivare a stime ancora più precise. Ma l’xG rimane la fondamenta: capirlo bene è la precondizione per valutare correttamente qualsiasi sistema più avanzato.
Prodotto dalla redazione di «Scommesse Calcio Come Vincere».




